- sales@hot-mining.com +86 28 8331 1885 +86 15196677188
-

-

-

The global clean-energy transition is driving demand for critical minerals at an unprecedented pace, while the mineral processing stage faces two core challenges:
●Feed grade keeps declining.
●Process dynamics are extremely complex.
Feed composition and mineralogical properties fluctuate constantly, and process mechanisms are difficult to model precisely. As a result, large amounts of valuable minerals are lost with tailings, creating both economic losses and environmental pressure.
Traditional concentrators rely mainly on process control to stabilize production. PID controllers remain the mainstream approach, and model predictive control (MPC) is often treated as an “advanced” method. But in essence, these methods follow a logic of “stabilize first, optimize later.” Under highly uncertain conditions, that logic often reaches its limits.
A Stanford University research team has proposed a new way to approach the problem: explicitly model mineral processing as an optimization problem under uncertainty. The core framework is the partially observable Markov decision process (POMDP).
Using a simplified flotation cell as an example, the team shows how “belief updates” can enable information gathering and decision optimization at the same time. In simulation experiments, the method significantly outperformed traditional deterministic approaches.
This article systematically walks through that technical path, with a focus on explaining the core algorithmic logic behind POMDP.
1. The Bottleneck of the Traditional Control Paradigm
Uncertainty in mineral processing mainly comes from two dimensions:
State uncertainty: Feed composition, particle size, and mineral liberation fluctuate in real time and are difficult to measure precisely throughout the full process.
Model uncertainty: Our understanding of mechanisms such as flotation kinetics, hydrodynamics, and surface chemistry contains bias. Any mechanistic model is only an approximation.
PID control can only handle single-variable or simple multivariable systems, and its effectiveness is limited for nonlinear, strongly coupled flotation circuits.
Although MPC introduces a predictive model, it depends heavily on an accurate deterministic model. Once the model no longer matches reality, or the feed fluctuates sharply, performance drops significantly.
Mineral processing optimization should not stop at "stable operation." It should directly target economic objectives, such as net present value (NPV), and make active decisions under uncertainty.
2. POMDP: From"Control" to "Sequential Decision Optimization"
POMDP, or the partially observable Markov decision process, is a standard framework for sequential decision-making under uncertainty.
Its biggest difference from traditional control is that it does not assume the system’s true state can be fully known. Instead, it represents uncertainty through a "belief."

The seven-element definition of a POMDP (S, A, O, T, R, Z, γ)
S: the true state space, such as feed composition and process dynamics, which cannot be fully observed
A: the action space, such as control parameters and whether to take a measurement
O: the observation space, such as sensor data
T: the state transition function
R: the reward function, usually tied to an economic objective such as NPV
Z: the observation function
γ: the discount factor
The core mechanism is straightforward: the agent selects an action based on its current belief - a probability distribution over the true state - receives a reward and a new observation, and then updates that belief.
The key innovation in belief updates
The research team uses Gaussian processes to model two types of uncertainty separately:
Sequential fluctuations in feed composition, which correspond to state uncertainty.
Systematic errors between the mechanistic model and the actual product grade or recovery, which correspond to model uncertainty.
Every time a new measurement is obtained, the Gaussian process is refitted sequentially. The belief mean curve gradually approaches the true value, while the uncertainty interval, or variance, shrinks at the same time.
This enables the agent to truly “collect information while optimizing decisions.”

Figure. An example of belief at the end of the simulation. Occasional measurements, shown as black dots, are used to update the belief and its associated uncertainty, shown as the blue region.
Solution algorithm: the POMCP online solver
The authors use POMCP, or Partially Observable Monte Carlo Planning, implemented through Monte Carlo tree search (MCTS).
At each decision point, the algorithm samples a large number of future trajectories from the current belief and uses an Upper Confidence Bound for Trees (UCT) strategy to quickly explore the optimal action. This makes it especially suitable for real-time industrial scenarios.
3. Complete POMDP Modeling of a Flotation Cell
The study uses a batch mechanical flotation cell as the example. This setup is convenient for laboratory validation and can later be extended to continuous flows. Most parameters are based on phosphate flotation.
3.1. State
Feed composition c (%)
Concentrate recovery r (%)
Concentrate grade g (%)
Time step T

Figure. A simple POMDP formulation for a flotation cell. The diagram also includes other possible state variables and control parameters beyond the formula scope of the article, shown here as examples.
3.2. Action
Flotation time t (min)
Air flow rate f (L/hr)
Whether to measure the feed, as an optional action
3.3. Reward function - directly targeting economic value
reward = [500g ($/t) · 35r (Mt/yr)] / [100 (timestep/yr)] - OPEX ($M/timestep)

Operating cost:
OPEX = (1/2)t + (1/50)f ($M/timestep)
![]()
This reward function fully captures the trade-off among grade, recovery, and energy consumption.

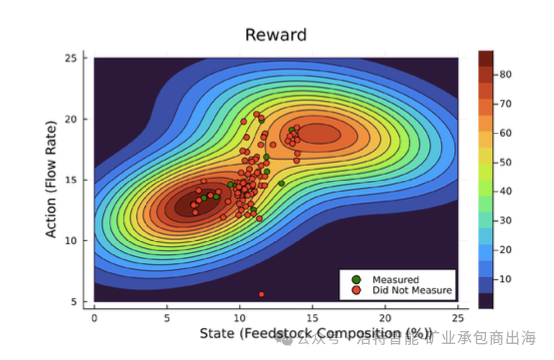
Figure. An example reward surface, where reward is treated as a function of state and action. It shows how the agent balances the cost of taking measurements against the cost of not taking action. The action is executed as the state fluctuates over time. Red dots indicate time steps when no measurement was taken, while green dots indicate time steps when a measurement was taken.
3.4. Initial mechanistic model, or prior
Recovery:
r(k, t, f) = 100 · [kt / (1 + kt)] · [f / (f + 10)]

Grade:
g(c, k, t, f) = c · [1 + (1 - c / 42.2) · ((1 - exp(-kt / 10)) / (1 + exp(4 - 0.04f)))]
(k = 1 min⁻¹)

True value = mechanistic model + random error, modeled by a Gaussian process. The agent continuously corrects the error through measurement data, moving from "uncertain" toward "increasingly certain."
4. Simulation Validation: The Clear Advantages of POMDP
The researchers ran 100 time steps, equivalent to simulating 100 batches in one year, and compared three strategies:
PID controller, used as the baseline
Model predictive control (MPC)
POMDP, solved using POMCP
Key findings
When model accuracy is high, MPC is slightly better than POMDP.
When model uncertainty increases, the advantage of POMDP appears quickly. In low-accuracy scenarios, it achieves significantly higher rewards.
The greater the feed variability, the stronger the adaptive capability of POMDP.
When the feed is unknown, meaning state uncertainty is present, POMDP improves faster than MPC as the number of measurements increases, and it fully surpasses MPC after a certain threshold.
Core conclusion:
in a highly uncertain environment, POMDP is better at turning limited information into optimization gains through active learning and belief updates.
5. Practical Application Value and Outlook
The biggest highlight of this framework is that it deeply couples information gathering with decision optimization.
Near-term application scenarios
Optimization of laboratory flotation tests, using the paper’s code framework directly.
Optimization of industrial single-cell flotation operations, moving from batch processing toward continuous flows.
Mid- to long-term expansion directions
Hierarchical POMDP modeling of an entire flotation circuit or even a full concentrator.
Integrated mine-to-plant optimization.
Decision support across the full critical minerals supply chain.
No additional hardware is required. The framework can be deployed with existing sensors and computing resources. Because the decision process is based on MCTS, it also has a certain level of interpretability, making it easier for engineers to understand and intervene.
Conclusion
Mineral processing is moving from the era of “experience plus control” toward an era of “data plus intelligent decision-making.”
This Stanford study provides a rigorous mathematical framework and shows that, under high uncertainty, directly optimizing for the objective and using a belief mechanism to handle the unknown is more robust than traditional deterministic control.
For technical professionals in the industry, understanding the core logic of POMDP will become an important starting point for introducing advanced decision-making tools:
State cannot be fully observed → belief represents uncertainty → belief updates drive learning → sequential optimization.
We look forward to seeing more mineral processing engineers and AI researchers work together to push this direction toward industrial deployment.
Reference
William Xu et al., “AI-driven Optimization under Uncertainty for Mineral Processing Operations,” arXiv:2512.01977 (2025).